Our Errors, Your Gain: A System Design Cautionary Tale
How improving our architecture boost our performance by 450%

I've started to work as a software engineer at 2014, however, I started to write code at high-school.
My first language was Assembly, but still, I fall in love with the possibilities to make the computer to do as you wish, shortly after that I started to write in C.
Later on I studied a practical engineering in electricity, and during this time discovered that I preferred much more writing code than design electrical components.
As a result of this understanding I decided to switch and study bachelor degree in computer science in Reichman university, where the focus was of the Java language.
Today I'm working at SumUp using Kotlin, SpringBoot & Micronaut, Cassandra and Kafka
TL;DR: This article shares my experience with a temporary solution that turned into a long-term issue. I discuss the evolution of a service and how it improved its performance by over 450% in a few hours. The story highlights the importance of addressing temporary solutions and constantly evaluating system design to optimize performance.
Introduction
About four years ago, around the time I joined my previous employer, my manager at the time introduced me to one of the services my team owned. He opened the explanation with the sentence, "As the saying goes, nothing is more permanent than a temporary solution". More than five years have passed since this service was initially introduced, and it's still running in production.
In this article, I share a specific use case of the service and how we improved its performance by over 450% in just a few hours.
The Original System Design
Let's start by briefly looking at the system's original design. The system included a database that serves as the source of the data, a poller service that checks for changes in the source database every five seconds, and in case a change is found, it aggregates the data and stores it in a different database. Lastly, a Reader service is responsible for reading the aggregated data from the database and serving it to our clients.
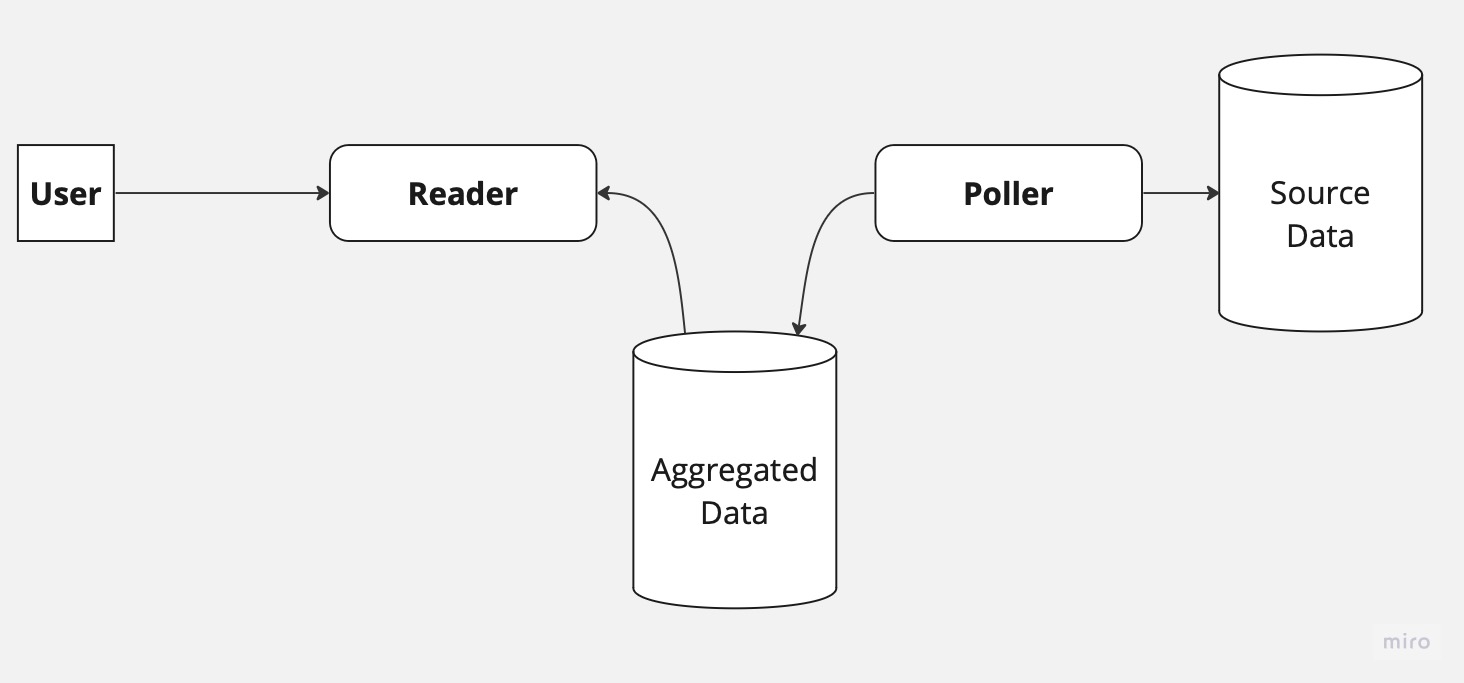
As you might already imagine, integration via a database is almost always a bad idea. It can lead to data inconsistency, lack of real-time updates, difficulty in making changes in the database schema, and more. But as we just said, temporary solution - right? Our system specifically suffered mainly from data inconsistency. The main root cause for the issues was been that the entities in the database might not yet be finalized by the time they were polled. In such a case, the poller would ignore the data and would never return to fix it later.

Addressing Data Inconsistency
Eventually, the data-owning team began publishing events indicating that the data was finalized and ready for use. We amended our poller service, so it would start to listen to those events and store the IDs of the entities that are ready to be picked in a table that it would later poll. This ensures no data is missed. With the new change, our system now looks as follows:
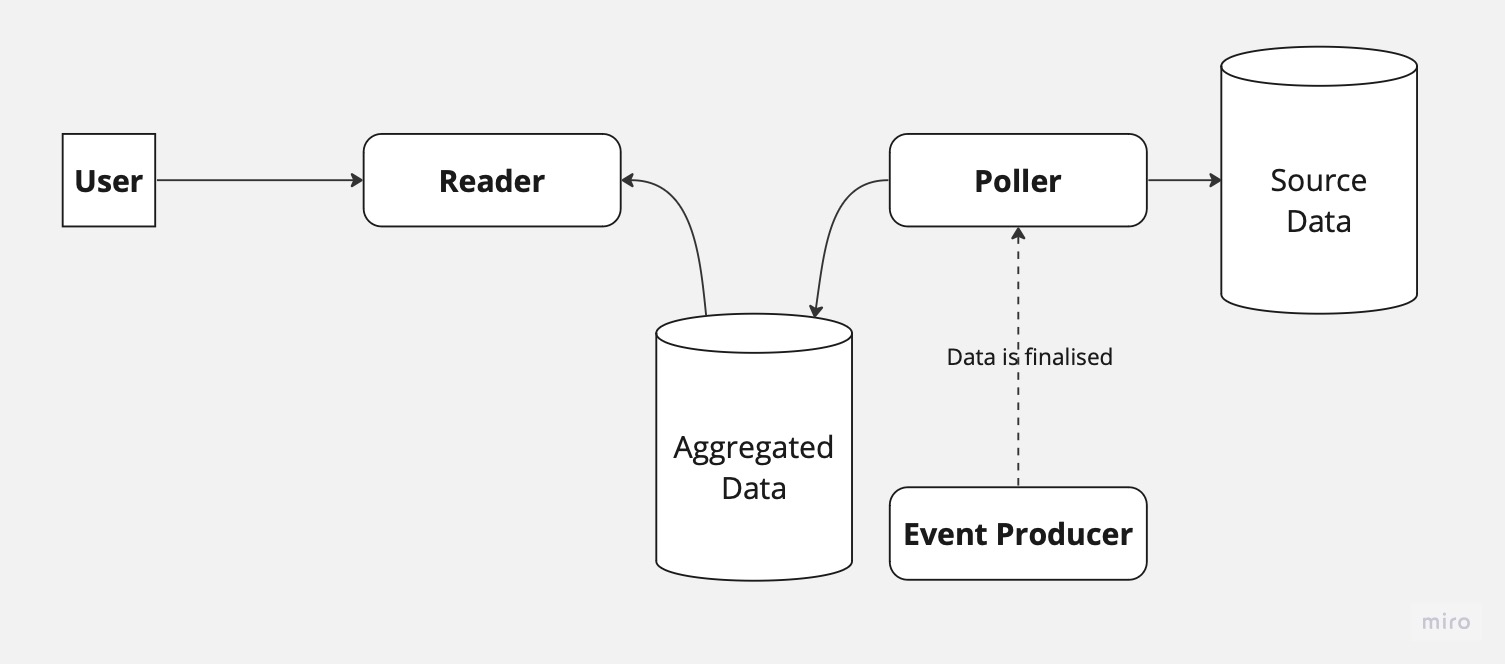
You might ask: "Why didn't you change the implementation to rely completely on the events?". Well... First, the events lacked the required information. The only reason the data exists in the database, to begin with, is because of domain mixing. The mix in domains has been so deep that multiple teams worked very hard for a very long time to split those domains.
The Human Error
At this point, it's worth stopping and discussing the human aspect behind the existence of this solution. The poller service was introduced as a technical solution for a technical problem. We needed access to data that we didn't have, and with the help of this service, we had that access (even if it caused a violation of multiple domain boundaries).
However, as we made the poller stable it fell lower and lower in the priority list of the company to replace this design with a proper solution. Not only that, but the maintenance of the service moved between teams in the company like a hot potato. In my time in the company, I actually had the pleasure of working on this system in 3 different contexts and teams.
The lack of real ownership of the system, higher company priorities, and management's general agreement that the solution wasn't great but worked, led to the repeated de-prioritization of refactoring this part of the system.
Introducing New Features and Challenges
The system functioned and was left unchanged for some time. Until one day, we had to introduce another new feature. The feature required to generate information for our clients about the previous day. The data should be available every day at 5 a.m. (client's local time).
To solve this problem, we first introduced a new service responsible for managing day opening/closing. Next, the poller service made a REST call to the new service for each entity in the database and assigned the ID of the current day. Lastly, the Read service aggregated the data from the database and used it to generate the required information.
Our system now looked like this:
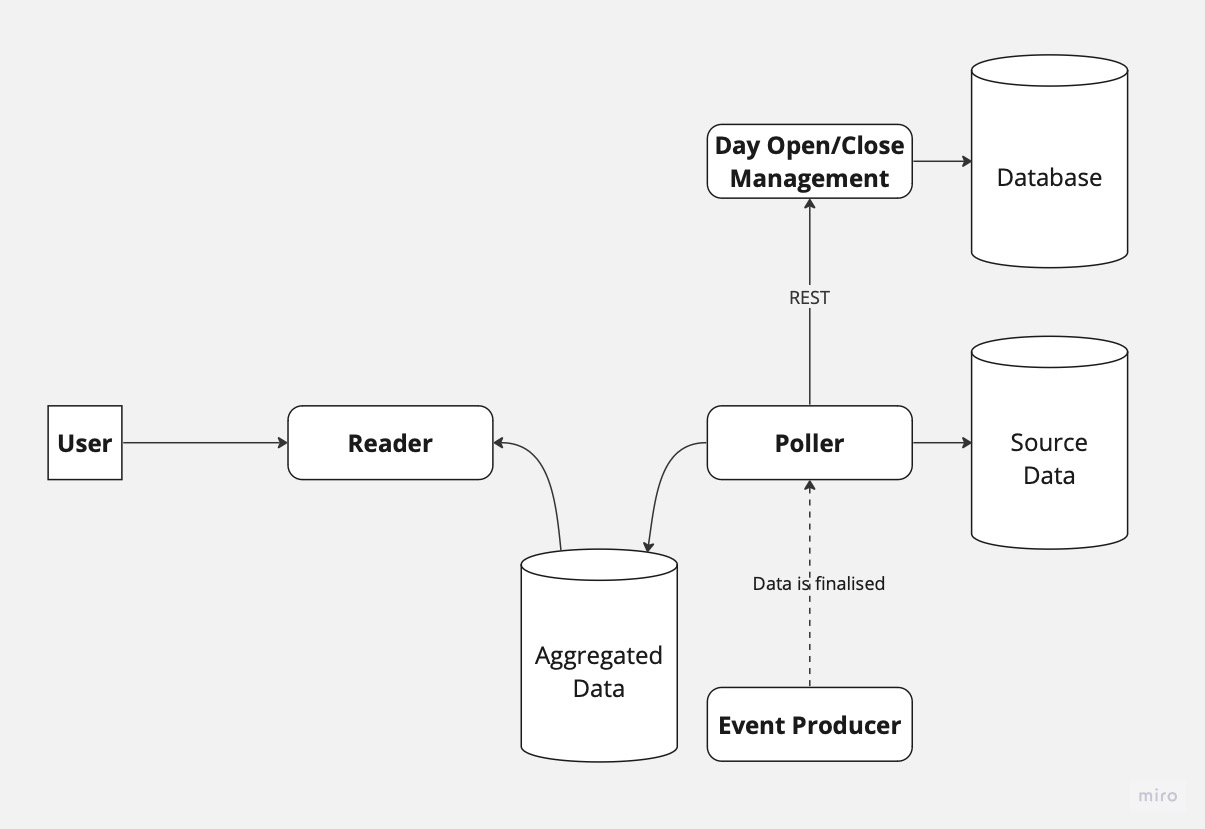
As you can imagine, using REST calls between the poller and the new service created a strong coupling. Every time we had to maintain the database of the day management service, our poller service received an internal error response from the REST call and did not assign an ID to the entity. We could resolve this situation by using asynchronous communication between the services. In such a case, the Day management service would notify all consumers whenever a new day is opened/closed and let them do as they wish with the information. Such a solution would allow scalability of the system, resiliency, and avoid coupling between the services (or as my favorite phrase says, building a distributed monolith).
Yet another issue, when the clients activated the feature, we did not assign the ID of the day to already existing entities. The impact of that was that the data from the first day was incomplete at best, or completely wrong at worst. This caused many calls to our support agents and wasted quite a significant amount of the team's time debugging the issue.

Performance Issues and Materialized Views
We rolled out the feature to 1000 clients. After about two weeks, we discovered that we had severe performance issues with our new feature. The issue was related to the SQL query we used to build the required information, which included multiple JOINs.
Since the data doesn't have to be updated during the day but only in the morning, we decided to come up with a new approach. We introduced a materialized view that was holding all the required information for the feature pre-calculated and refreshed the view every morning.
If you're unfamiliar with the materialized view in SQL, it is a database object that contains the results of a query, stored in a table-like structure. It is used to cache the results of complex queries for faster access and improved performance. Materialized views are periodically updated by refreshing the stored data, either manually or automatically, to keep the view in sync with the underlying data.
That means that from that point on, our poller started to refresh the materialized view every day. That was supposed to be a temporary solution until we find a more suitable database for our needs (where did I hear this before?)

At this point, I would like to stop and point out a few flaws in the above design with the requirements we had:
Since we rolled out in multiple time zones, and we had only one view, we could not serve the information for our client at 5 a.m. anymore; the refresh had to happen when the client with the latest timezone hit this time.
Materialized view does not support partial refresh, which means that every day we had to refresh all the data that was included in the feature, for all of our clients.

The solution kind of worked for a while. However, as the number of clients using the feature grew, and the amount of data we collected for each of them also grew, the refresh of the materialized view started to become heavy. It became so heavy that at some point it took almost 5 hours to refresh the view.
Not only did our API not match its target, but it also consumed a lot of resources from our database, which caused a lot of headaches for our database admins.
The Efficient Solution and its Benefits
Some time passed by, and a colleague of mine reached out to me and told me, "I think that I know how to fix the issue!". Instead of refreshing all the data every day, let's create a new table that would hold the pre-calculated data, we will run a job that would be executed periodically, and calculate only the delta since the previous calculation. The idea was genius by its simplicity!
We decided to make a POC for the above suggestion and check if it can be implemented. In six hours, we deployed a working POC in our staging environment, tested it, and with an additional day of work we went all the way to production.

After some testing, we set our refresh period to 1 minute and noticed that the query takes now around 1.4 seconds to be executed. With that, our saga came to an end.
As you can see in the graph below, our CPU usage for the database dropped dramatically after the changes!

With those changes, we regained:
Minimal resource consumption by the database.
Near-real-time information availability for clients instead of a 5-hour delay
Simpler, easier-to-understand codebase.
To Be Continue?
While the story of the poller does not end here, my story in the company does. After almost 4.5 years I contacted my first manager in the company and told him that I had failed to sunset the poller. However, there is good news on the horizon. A new dedicated team starting to work now on re-writing the entire system from the ground, basing it on the right data sources, and hopefully soon enough the poller story will come to an end! 🤞
Conclusion
This cautionary tale demonstrates the importance of addressing temporary solutions and constantly evaluating system design to optimize performance. By implementing a more efficient approach to handling growing data and client needs, the team significantly improved their system's performance, resource consumption, and overall simplicity.
Remember, temporary solutions are never temporary!
Every tech debt decision you make will come back and hunt you if you are not going to come back and fix it later.



